![[OPUS]](gif/opus.gif)
INPATH = gif_data ! Directory where the input files are found OUTPATH = fits_data ! Directory where output files are writtenIt is the path file which binds those logical names to physical directories. The symbolic names are resolved by the path file where you will find something like:
gif_data = /home/mydir/opus_test/dat/ fits_data = /home/mydir/pipe/out/This allows you to create several independent pipelines without having to change either code or the process resource files. All you need to do to define a distinct pipeline is a new path file.
~/opus_test/definitions/
~/opus_test/definitions/But, rather than hunt for this file, you can have the Process Manager (PMG) display the path file. Under the "File" menu, click on the "Select Process.." option.
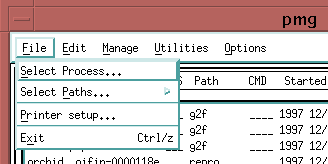
Double-click on the name of the path, and the path file will be displayed.
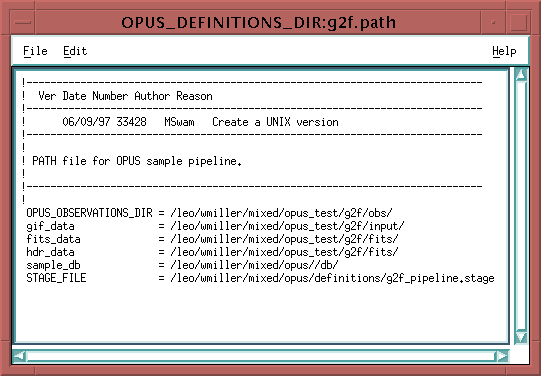
babylon5.path ! correct xfiles.path ! correct nine_char.path ! correct samplepipe.path ! incorrect more_than_nine_char.path ! incorrectEach path file must use the extension ".path". The format of the path file contents is similar to a process resource file. Exclamation points are used to delimit comments, either in-line or at the beginning of a line; there are keywords and values in the path file separated by equal signs.
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! ! this is a comment line !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!(so is this)!!!!!!!!!!!!!!!! KEYWORD = value !commentUnlike the process resource file, an override path file is not allowed. That is, path files with the same name are not allowed within the OPUS_DEFINITIONS_DIR stretch.
Keywords other than those that define directories can reside in the path file, and each of these keywords is accessible to the tasks which are running in that path. For example, the default database for the pipeline tasks can be set in the path file:
OPUS_DB = OPUSTEST !Database for testingBut this can be overridden by an identical keyword in the process resource file.
It's the other way around. If a process resource file has a keyword which has an identical keyword in a path file, then the process resource file takes precedence.
The precedence rules between path keywords and resource file keywords are a little elaborate.
ENV.OK_TO_UPDATE_DATABASE = TRUE !in the getkw process resource file GETKW.OK_TO_UPDATE_DATABASE = FALSE !in the path fileThen when the getkw task inquires about the value of the OK_TO_UPDATE_DATABASE environment variable, it will be FALSE (recall that the ENV. prepended to the keyword name is not part of the name itself, but instead is a command telling OPUS to set this keyword and value in the process' environment).
*." to the keyword name:
ENV.OK_TO_UPDATE_DATABASE = TRUE !in the process resource file *.OK_TO_UPDATE_DATABASE = FALSE !in the path fileThen when any task inquires about the value of OK_TO_UPDATE_DATABASE, it will be FALSE.
ENV.OUTDIR = fits_directory !in process resource file fits_directory = /home/test/fits/ !in the path fileThen when the task inquires about the value of OUTDIR, the path "/home/test/fits/" will be returned.
ENV.DSQUERY = nomad !in the process resource file DSQUERY = daneel !in the path fileThen when the task inquires about the value of DSQUERY, the value "nomad" will be returned.
ENV.OUTDIR = TTAG_CALIB_DIR !The timetag calibration directoryThe physical names of the directories are usually maintained in the path file where, for example, you might see:
TTAG_CALIB_DIR = /home/opus/ttag_data/calib/ !calibration directoryOPUS guarantees that the translation of the environment variable is done before the task is actually started, so the task can use $OUTDIR and be assured that the right path will be substituted. This indirection allows the same process to run in several different paths without changing the process resource file. If TTAG_CALIB_DIR is not defined in the path file, then $OUTDIR will literally be a directory of the name "TTAG_CALIB_DIR". Additionally, OUTDIR is an environment variable available only to the process(es) in whose process resource file it is defined. Also note that it is the value defined in the process resource file that becomes the environment variable, not the entry found in the path file.
It is possible to construct a "bridge" task. A process in one pipeline can, for instance, create a file in another pipeline. The existence of that file might trigger new actions in the second pipeline. For example, assume the process resource file for the first task contained the following keyword:
ENV.OUTDIR = blue->INPUT_DIR !Send data to another pipelineAssume, further, that the first task is just a shell script which wants the "blue" path to be notified of an event. That first task need only create a notification file in the directory where the process in the second (blue) pipeline is expecting notification. For example:
%touch $OUTDIR/F93874592_notification.fndOPUS takes care of the translation between the symbol OUTDIR and the actual directory used by the second process. That directory is normally specified in the blue.path file as some physical directory, for example:
INPUT_DIR = /home/mydir/blue/notify/ !notification directory
It is consequently a good idea, but not required, to use uppercase for the process resource file keywords that will be placed in the environmnent.
Each path also must be linked to a pipeline stage file that defines the processing stages for that path. If this file is named [path]_pipeline.stage, where [path] is the root name of the path, and located in OPUS_DEFINITIONS_DIR, then the pipeline stage file need not be defined in the path file. However, if a different file name or location is chosen, the STAGE_FILE keyword must be present in the path file, and it must indicate the complete pipeline stage file specification.
For example, a path called "blue" might contain the following lines in its path file.
STAGE_FILE = OPUS_DEFINITIONS_DIR:blue_pipeline.stage OPUS_OBSERVATIONS_DIR = /home/mydir/blue/observations/